
Artificial intelligence (AI) has rapidly revolutionized the way we live, work, and communicate. The latest phenomenon, ChatGPT from OpenAI, has become a tipping point that quickly spiked to over 100 million users in just two months, according to The Guardian, and has stunned the world with its ability to produce high-quality answers to complex topics. It has also left us puzzled by awkward hallucinations and made-up facts masqueraded in professional language. How to take advantage of available tools to elevate our human lives without creating more problems is still a complex puzzle that requires continuous discussions and debates.
Members of the panel included the Chair of the webinar – Dr. Xuedong Huang, an expert in the field of speech and language processing with 30 years of experience at Microsoft. Dr. Huang is Microsoft’s Technical Fellow and Azure AI Chief Technology Officer. He is also a member of the VinFuture Prize Council. Recently, he became a member of the American Academy of Arts and Sciences.
The distinguished speaker of the webinar was Dr. Vinton Cerf – Vice President & Chief Internet Evangelist at Google; one of the Laureates of the 2022 VinFuture Grand Prize. He is widely known as one of the fathers of the Internet and his speech presented LLMs’ remarkable ability to generate relevant content but also alternative facts.
The special guest of the webinar was Dr. Jianfeng Gao – Distinguished Scientist & Vice President at Microsoft Research. He is leading the development of AI systems for natural language processing, web search, vision language understanding, dialogue, and business applications. Dr. Gao focused on the concept of augmenting LLMs with a plug-and-play model to fill the functional gap for mission-critical tasks.
Representing the Vietnamese Sci-Tech community in AI field was Dr. Hung H. Bui – the Founder and CEO at VinAI, a former expert at Google DeepMind, Adobe Research, and Nuance Natural Language Understanding Lab, and AI Center at SRI International. Dr. Bui shared insights on the opportunities and challenges for LLMs development for low-resource languages.
The discussion attracted nearly 240 attendees, including scientists, academic researchers, inventors, and entrepreneurs in science and technology from across the world.
Unprecedented abilities, unprecedented problems
ChatGPT is a tool driven by AI technology, specifically LLMs, that allows users to engage in human-like conversations based on the knowledge it has absorbed. With the availability of tremendous computing resources and continuous technological improvements, ChatGPT has demonstrated the capacity to generate high-quality, grammatically correct texts with convincingly relevant content.
Impressive as it may be, ChatGPT is certainly not the only LLM-based technology in the market, as highlighted by Dr. Xuedong Huang, the panel chair. Since the 1950s, AI developers have discovered that a statistics-based approach to speech recognition, which forms the core of LLMs, is highly effective for machine translation. IBM, Microsoft, and Google have made continuous investments in the advancement of LLM technology.
Nowadays, there are hundreds of LLMs available for us to utilize, but there are still many challenges to overcome. “No one can claim to have the exact recipe to solve this problem yet,” said Dr. Huang. This is why he believes that bringing together world-class experts, like in this event, can foster valuable discussions and further the advancement of this field.

Dr. Vinton Cerf: Large Language Models are erratic but intriguing
Dr. Vinton Cerf initiated the conversation by expressing his personal concerns regarding his interactions with ChatGPT. From his perspective, LLMs have demonstrated an impressive ability to generate well-formed and largely relevant content of relatively good quality. However, due to this high quality and format, it becomes confusing to differentiate between AI-generated products and those created by human beings.
“The father of the Internet” is impressed by the capabilities of LLMs, but what perplexes him even more is their propensity for inventing “alternative facts.” According to him, the prevalent method of statistical training and reward mechanisms for generating fill-in-the-blank texts has inadvertently contributed to this phenomenon.
Dr. Cerf shared an example of when he asked LLMs to write his own obituary. Given the availability of his biography and life records on the World Wide Web, LLMs promptly generated a 700-word obituary; however, it contained inaccurate information.
“An obituary form was created, providing some history of my life and contributions, and it got many things wrong. It gave me credit for things that other people did, and other people were credited with the things I did. And then at the end, as a typical obituary, it wrote about members of the family left behind. It’s made up of family members I don’t have,”
Dr. Cerf told the audience.
He referred to this phenomenon as the “salad-shooter” effect, where truths, like vegetables, are fragmented and mixed together to create a random “word salad” dish. While this can be advantageous in creative tasks, Dr. Cerf’s primary concern is the risk of being persuaded by the seemingly high quality of incorrect outputs, particularly for individuals who are unfamiliar with the subject matter. Blindly accepting AI-generated answers as truths becomes risky, especially in scenarios such as medical advice or evaluating medical conditions.

He proposed the need for specific risk analysis in different categories and suggested the development of constraining methods for LLMs to encourage constructive applications and deter harmful behaviors.
“We might have an artificial Id and an artificial Ego but we don’t have an artificial Super Ego that will kind of oversee what’s going out of the chatbot and put some constraint on it. Maybe we need two chatbots, one is doing the generative stuff and the other sitting on the top of it saying ‘hey, you might go off the rail already’,”
Dr. Cert said.
Dr. Jianfeng Gao: From LLMs to Self-Improving AI
Dr. Jianfeng Gao, a Distinguished Scientist and Vice President at Microsoft Research, provided further insights into the fundamental issues surrounding ChatGPT and its “specific to general: one LLM for all” approach. He highlighted three major problems:
The first problem is hallucination, which stems from the lossy encoding of knowledge. This model compresses the indexing of the entire World Wide Web, and due to the vast amount of data, it results in memory distortion, similar to what occurs in the human brain.
The second problem is the lack of task-specific knowledge that was unseen during the training of LLMs. Regardless of the size of the databases, this model cannot encompass everything. The most common omissions include daily news (which is too regularly updated for the model to keep pace with) and specialized datasets that are not publicly available.
While hallucination can be beneficial for creative purposes, such as writing a novel, it becomes problematic when it comes to information-seeking tasks. This leads to the third problem: the “one LLM for all” approach does not allow for self-improvement in task-specific skills and objectives.
Dr. Gao suggested various ways to adjust the model, but ideally, the models “need to be able to adapt themselves based on the context.” He proposed the development of a self-improving AI model that constantly enhances itself while learning new skills for different tasks. This approach aligns with the transition in evaluating LLM intelligence from “skill on a task” to “skill acquisition efficiency.”
The system involves augmenting LLMs with plug-and-play (PnP) modules to bridge the functional gap of LLMs for mission-critical tasks like Web QA, image editing, and text-driven code generation for data analysis.

The PnP model involves modifying LLM inputs (e.g., prompting, user intent encoder), LLM outputs (e.g., task-specific decoder, automated feedback), and the data flow of LLM using residual connections (e.g., LoRA adapter, task-specific entity/object detector). This addresses the issue of LLM processing commonly viewed as a black box.
Additionally, the self-improving AI system adapts based on user interactions and automated feedback. It aims to make existing modules more efficient and reusable, while also discovering new skills through module composition and creation.
Microsoft’s AI Copilot is provided as an example, which leverages both LLM (ChatGPT) and LLM-Augmenter approaches. The utility function acts as a judge, providing utility scores and feedback to address the hallucination issue. This utility function aligns with Dr. Cerf’s earlier concept of an “AI Super Ego.”
Dr. Hung H. Bui: ChatGPT is not ready for half of the world’s population
From Dr. Hung H. Bui’s perspective, the unprecedented adoption rate of ChatGPT has highlighted its lack of readiness to serve more than half of the global population who do not use English as their first language. As the founder and CEO of VinAI, he places great importance on low-resource or non-mainstream languages.
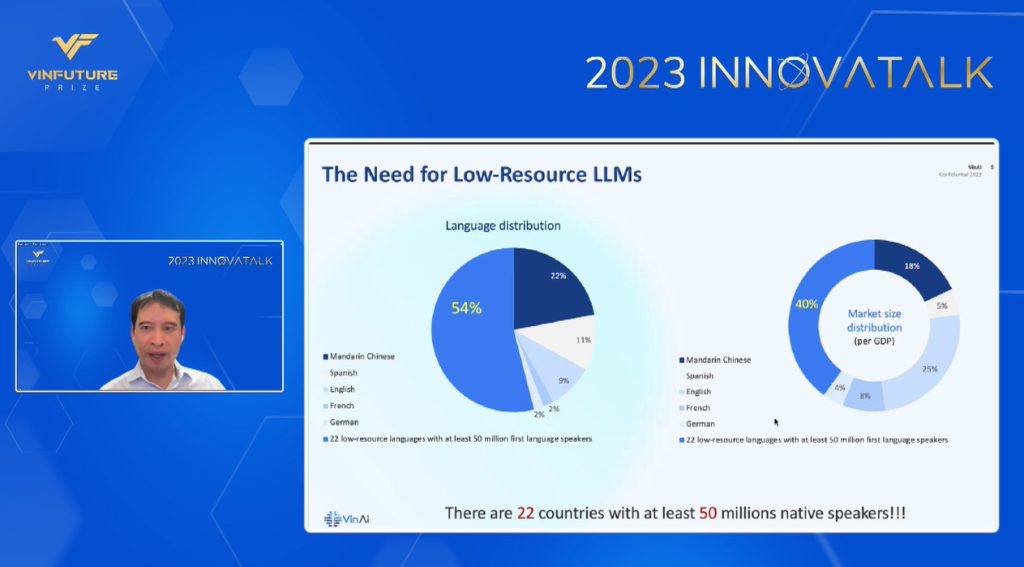
Dr. Bui’s analysis revealed that there are at least 22 countries with at least 50 million native speakers that fall into the low-resource language category. In terms of GDP, these combined populations make up at least 40% of the world’s total. “We are faced with the reality that technologies like ChatGPT are not yet prepared for them,” stated Dr. Bui.
The lack of high-quality pre-trained LLMs and publicly available large-scale, high-quality corpora for low-resource languages is a significant issue. Insufficient resources and limited knowledge exacerbate the problem of hallucination, leading to the generation of made-up facts and unnatural texts.
Dr. Bui proceeded to use Vietnamese as an example to illustrate the relatively lower and less efficient performance of ChatGPT in low-resource languages. He presented two instances where ChatGPT failed to provide accurate answers to questions about a popular Vietnamese novel “Tắt Đèn” (in English: When the light is out) by the author Ngo Tat To and a popular 2001 pop song “Cây đàn sinh viên” by the singer Mỹ Tâm. These are facts that most Vietnamese individuals would be familiar with, but ChatGPT provided completely incorrect answers, stating that famous musician Trinh Cong Son wrote the song “Cây đàn sinh viên” in 1958.
At VinAI, Dr. Bui’s team has conducted experiments to develop Vietnamese-specific LLMs to address this problem. Although significant training and fine-tuning are required, this experiment has demonstrated the potential to tackle one of the critical challenges in LLM models for low-resource languages. The underlying reason may simply be a lack of locally-specific and culturally-specific training data.
According to Dr. Bui, low-resource LLMs must possess emerging capabilities in in-context learning, instruction following, and step-by-step reasoning while maintaining computational efficiency. This will enable new markets and use cases in local regions and enhance the responsibility and trustworthiness of LLMs for users.
“Low-resource LLMs are one of the keys to democratizing LLMs technology to the world, and Vietnamese is a great test.” Dr. Bui said. He hopes that major tech companies will pay greater attention to non-mainstream languages and join the path to bring the benefits and accessibility of AI technology to people regardless of their geographical location.
Discussion: How to utilize AI for the betterment of humanity
The panel initiated a discussion on the risks associated with human-like chatbots in accuracy- and safety-critical areas such as healthcare (e.g., medical diagnoses) and finance (e.g., financial transactions). How can we ensure that AI produces safe responses?
Dr. Gao emphasized the importance of setting realistic expectations for the system’s limited capabilities. Taking gradual steps forward is crucial to ensure that users and industries are well-prepared for this change.
“I think we should give the LLM the ability to say ‘I don’t know’,” Dr. Bui suggested. Dr. Cerf appreciated the idea and raised both thumbs in agreement. Dr. Bui emphasized that saying ‘I don’t know’ should be considered as a last resort, rather than training LLMs to fabricate answers that could have consequences.
When addressing a student’s question about the possibility of shortening the training process for LLMs by correcting ChatGPT in real-time, Dr. Bui shared that such a process might be achievable through fine-tuning the model. However, it would require significant engineering efforts. Moreover, the crucial task is not about adding more data, but rather improving the computational efficiency of the current technology with the available resources.
The impact of AI on education and examinations was also raised as an important topic by the audience. Dr. Cerf stated that with the popularization of AI, the focus should shift from solely evaluating students’ answers to understanding their reasoning process. While AI excels at producing results, what truly matters now is the explanation, the thought process, and the identification of any mistakes made.
Dr. Huang agreed and further emphasized that the rise of AI signifies a significant revolution in education, particularly in Asian countries, where the focus should transition from memorizing and regurgitating facts to learning the “know-how” of generating new knowledge for society. LLMs will play a role in checking potential mistakes and testing the application of human reasoning in the real world.
The goal of AI-driven technology is to improve and enhance human life rather than replace humans. The panel encouraged the audience not to worry but instead to learn how to wisely delegate tasks to AI.
“I think AI opens more opportunities, just as previous technology did. ChatGPT is only repeating, it is not adding anything. Our human work should be focused on creating new value,”
said Dr. Huang.
Dr. Gao specifically suggested that scholars outsource the demanding task of literature reviewing to ChatGPT while they focus on writing their research papers. “If the task is reviewing 300 pieces of literature which are mostly outdated, you should let ChatGPT do it while you spend more time watching movies with your family”, he said.









