
Trí tuệ nhân tạo (Artificial Intelligence – AI) đã tạo ra một cuộc cách mạng trong cuộc sống hàng ngày của con người. Sản phẩm ChatGPT của OpenAI gần đây đã tạo nên một kỷ lục mới khi thu hút hơn 100 triệu người dùng chỉ sau hai tháng chính thức ra mắt, theo The Guardian.
ChatGPT khiến cả thế giới ngạc nhiên với khả năng tạo ra những câu trả lời chất lượng, ngay cả khi được đặt cho các câu hỏi phức tạp. Tuy nhiên, vấn đề “ảo giác AI” (hallucination) và thông tin sai lệch được “ngụy trang” bằng ngôn ngữ chuyên nghiệp đang tạo ra những rủi ro cho cuộc sống con người. Các vấn đề này cần tiếp tục được tranh luận và trao đổi để tìm ra những hướng giải quyết triệt để trong tương lai. Hội thảo “ChatGPT và những thách thức” tập trung vào câu hỏi chính “Làm thế nào để tận dụng công nghệ AI mà không tạo thêm các mối nguy hại cho xã hội?”.
Chủ tọa của buổi hội thảo – TS. Xuedong Huang, thành viên Hội đồng Giải thưởng VinFuture – là chuyên gia hàng đầu thế giới trong lĩnh vực xử lý giọng nói và ngôn ngữ bằng AI. Ông có hơn 30 năm kinh nghiệm làm việc tại Microsoft và hiện là Chuyên gia Kỹ thuật kiêm Giám đốc Công nghệ của Azure AI. Ông cũng vừa được bầu làm viện sĩ của Viện Hàn lâm Khoa học và Nghệ thuật Hoa Kỳ.
TS. Vinton Cerf – Phó chủ tịch kiêm Chief Internet Evangelist tại Google, chủ nhân giải thưởng Chính VinFuture năm 2022 là diễn giả mở đầu cho buổi hội thảo trực tuyến. Tham luận của TS. Cerf bàn về năng lực đột phá của mô hình ngôn ngữ lớn không chỉ trong việc tạo ra nội dung chất lượng cao mà còn trong việc tạo ra các “sự thật sai lệch”.
TS. Jianfeng Gao – Nhà khoa học cao cấp kiêm Phó chủ tịch của Microsoft Research chia sẻ về mô hình ngôn ngữ lớn tăng cường (augmenting LLMs) và mô hình plug-and-play (PnP) nhằm cải thiện các lỗ hổng chức năng khi AI thực hiện các nhiệm vụ chuyên biệt. Trong công việc của mình, ông là người dẫn dắt việc phát triển hệ thống AI trong các lĩnh vực xử lý ngôn ngữ tự nhiên, tìm kiếm trên web, phân tích ngôn ngữ hình ảnh, hội thoại cũng như các ứng dụng liên quan đến kinh doanh tại tập đoàn này.
Đại diện cho cộng đồng khoa học – công nghệ Việt Nam trong lĩnh vực AI tại buổi tọa đàm là TS. Bùi Hải Hưng – Tổng Giám đốc của VinAI. Ông từng làm việc tại nhiều tổ chức khác nhau như Google DeepMind, Adobe Research, Nuance Natural Language Understanding Lab, và AI Center tại SRI International. Trong buổi webinar, TS. Hưng bàn về cơ hội và thách thức trong việc phát triển các mô hình ngôn ngữ lớn đối với các ngôn ngữ ít tài nguyên (low-resource languages).
Buổi hội thảo thu hút gần 240 người tham dự, bao gồm giới khoa học, giới nghiên cứu học thuật, các nhà sáng chế cũng như doanh nhân trong lĩnh vực khoa học và công nghệ từ nhiều nơi trên thế giới.
Năng lực vượt trội cùng với thách thức chưa có tiền lệ
ChatGPT là một chatbot ứng dụng công nghệ AI, cụ thể là mô hình ngôn ngữ lớn. Công cụ này có khả năng tương tác với người dùng thông qua những đoạn hội thoại bằng văn bản giống hệt như do con người tạo ra, dựa vào hệ thống kiến thức mà máy tính đã thu nạp. Với tài nguyên điện toán khổng lồ và những cải tiến công nghệ liên tục, ChatGPT đã chứng tỏ khả năng đáng kinh ngạc trong việc tạo ra các văn bản chất lượng cao, đúng ngữ pháp và đáp ứng nội dung yêu cầu một cách thuyết phục.
Theo TS Xuedong Huang – chủ tọa buổi hội thảo, ChatGPT đến nay là sản phẩm ấn tượng nhất, nhưng không phải là sản phẩm đầu tiên và duy nhất ứng dụng LLMs. Từ những năm 1950, các kỹ sư AI đã phát hiện ra rằng phương pháp nhận dạng giọng nói dựa trên phương pháp tiếp cận thống kê (cốt lõi của mô hình ngôn ngữ lớn) đặc biệt hiệu quả trong công nghệ máy học. Các công ty công nghệ lớn như IBM, Microsoft và Google đã liên tục đầu tư phát triển công nghệ này.
Hiện nay có đến hàng trăm mô hình ngôn ngữ lớn đang vận hành, nhưng vẫn còn rất nhiều vấn đề tồn đọng. “Không ai có thể tuyên bố họ có công thức chính xác để giải quyết các vấn đề trên,” TS. Huang nói. Đó là lý do ông cho rằng những dịp quy tụ các chuyên gia trên thế giới như buổi hội thảo trực tuyến này là rất quan trọng, để các cuộc thảo luận luôn được tiếp nối nhằm thúc đẩy sự phát triển của AI hướng đến những mục tiêu tốt đẹp.

TS. Vinton Cerf: LLMs tuy thất thường nhưng hấp dẫn
TS. Vinton Cerf bắt đầu phần trình bày với các trải nghiệm cá nhân khi tương tác với ChatGPT. Theo ông, mô hình ngôn ngữ lớn đã thể hiện khả năng ấn tượng trong việc tạo ra nội dung có định dạng hoàn thiện, ngữ pháp chính xác, cũng như nội dung phù hợp với chất lượng tương đối cao. Tuy nhiên, chính khả năng đó đã tạo nên sự bối rối cho người dùng vì không biết tác giả là máy hay là người.
TS. Cerf rất ấn tượng với khả năng của LLMs nhưng ông băn khoăn nhiều hơn về việc LLMs cũng đồng thời là những cỗ máy tạo ra nhiều thông tin sai lệch. Theo ông, cách thức đào tạo dựa trên phương pháp tiếp cận thống kê, cũng như việc khuyến khích khả năng AI tạo ra văn bản dạng điền vào chỗ trống, đã vô tình dẫn đến hiện tượng này.
TS. Cerf kể lại lần ông yêu cầu một mô hình LLM viết cáo phó cho chính mình. Chatbot ấy nhanh chóng tạo ra được một bản cáo phó 700 chữ do đã có tương đối nhiều thông tin tiểu sử và các thành tích của ông được đăng tải trên trên Internet. Tuy nhiên, văn bản này chứa đầy những thông tin không chính xác.
“Nội dung của bản cáo phó ấy đã tóm lược được một vài thông tin về cuộc đời cũng như các đóng góp của tôi. Tuy nhiên, có rất nhiều thứ không chính xác. Nó gán cho tôi những thành tựu của người khác, và ngược lại. Bản cáo phó này cũng nhắc đến các thành viên gia đình còn lại khi tôi mất đi, theo công thức quen thuộc, nhưng đó toàn là những nhân vật hư cấu.”
TS. Cerf gọi đây là hiệu ứng “salad-shooter”, khi sự thật được cắt ra thành các mảnh nhỏ và trộn lẫn ngẫu nhiên với nhau, như khi chúng ta làm món salad rau củ. Các kết quả sai lệch dưới dạng ngôn ngữ chuyên nghiệp này có thể dễ dàng đánh lừa người dùng nếu như họ không hiểu rõ về chủ đề. Việc chấp nhận một cách mù quáng các câu trả lời do AI tạo ra sẽ có rủi ro lớn, đặc biệt trong các tình huống như tư vấn y tế hoặc đánh giá tình trạng bệnh lý.

Ông cho rằng cần có những phân tích rủi ro cụ thể cho từng lĩnh vực cũng như phương pháp giám sát, nhằm ngăn chặn các hành vi gây hại và khuyến khích các ứng dụng tốt của LLMs.
“Chúng ta có thể đã có “bản năng nhân tạo” (artificial Id) và một “bản ngã nhân tạo” (artificial ego), nhưng chúng ta chưa có một “siêu ngã nhân tạo” (artificial super-ego) để giám sát tiêu chuẩn và giảm thiểu hành vi rủi ro cho các kết quả đầu ra của những mô hình ngôn ngữ lớn. Có lẽ chúng ta cần hai chatbot hoạt động cùng một lúc, một cái tạo ra kết quả và cái còn lại có nhiệm vụ nhắc nhở khi kết quả đi chệch hướng,”
TS. Cerf bình luận.
TS. Jianfeng Gao: Từ LLM đến AI tự cải thiện
TS. Jianfeng Gao – nhà khoa học cao cấp kiêm Phó chủ tịch Microsoft Research tiếp nối mạch thảo luận bằng việc nêu ra ba vấn đề lớn liên quan đến ChatGPT và cách tiếp cận đi từ chi tiết đến tổng quát của mô hình này. Nó được hiểu nôm na là mong muốn xây dựng một mô hình ngôn ngữ lớn áp dụng cho tất cả các nhiệm vụ.
Vấn đề đầu tiên là “ảo giác AI” (hallucination), bắt nguồn từ việc kiến thức bị rơi rớt trong quá trình mã hóa và giải mã dữ liệu. Mô hình này thu nạp tất cả mọi thứ trên mạng World Wide Web, và lượng dữ liệu khổng lồ đó đã gây biến dạng bộ nhớ, tương tự những gì xảy ra ở não người.
Vấn đề thứ hai là thiếu kiến thức về các nhiệm vụ chuyên biệt, và điều này không được nhận biết trước trong quá trình đào tạo LLMs. Mặc dù quy mô của cơ sở dữ liệu có lớn như thế nào thì LLMs cũng không thể nạp được tất cả mọi thứ. Những thiếu sót phổ biến nhất có thể kể đến là tin tức hàng ngày (do tốc độ cập nhật tin quá thường xuyên so với việc cập nhật mô hình), hay những bộ dữ liệu chuyên ngành không được công khai.
Vấn đề “ảo giác AI” và “bịa” ra các câu trả lời không đúng thực tế có thể có ích cho các mục đích sáng tạo, chẳng hạn như viết tiểu thuyết. Tuy nhiên, đây lại là vấn đề nghiêm trọng trong các tác vụ cần tìm kiếm thông tin chính xác. Điều này dẫn đến vấn đề thứ ba của ChatGPT: chưa có khả năng tự cải thiện khi được giao các nhiệm vụ mang tính chuyên biệt.
TS. Gao cho rằng có nhiều cách để khắc phục, nhưng lý tưởng nhất là các mô hình phải có khả năng “tự điều chỉnh dựa trên bối cảnh”. Ông đề xuất phát triển một mô hình AI có khả năng tự cải tiến, đồng thời học các kỹ năng mới cho các nhiệm vụ khác nhau. Cách tiếp cận này cũng phù hợp với tiêu chuẩn mới khi đánh giá các LLMs, đó là xem xét hiệu quả tiếp thu kỹ năng thay vì hiệu quả trong từng tác vụ riêng lẻ.
Hệ thống này tập trung vào việc phát triển mô hình ngôn ngữ lớn tăng và các mô-đun cắm-và-chạy (Plug-and-Play/PnP). Cách tiếp cận này giúp giảm dần các thiếu sót chức năng của LLMs trong các nhiệm vụ quan trọng như Web QA (đảm bảo chất lượng website), chỉnh sửa hình ảnh, hay tạo các đoạn mã dựa trên văn bản để phân tích dữ liệu.
Mô hình PnP bao gồm việc chỉnh sửa dữ liệu đầu vào của LLMs thông qua lời nhắc, mã hóa ý định người dùng, sau đó chỉnh sửa đầu ra qua việc giải mã dành riêng cho từng tác vụ, phản hồi tự động, và cuối cùng là chỉnh sửa luồng dữ liệu sử dụng kết nối phần dư (residual connections), như bộ điều hợp LoRA hay máy dò dành riêng cho tác vụ. Điều này giải quyết được các “hộp đen” trong quá trình LLMs vận hành.

Ngoài ra, hệ thống AI tự cải thiện có thể điều chỉnh dựa trên tương tác của người dùng và các phản hồi tự động. Điều này sẽ khiến các mô-đun sẵn có trở nên hiệu quả hơn và có thể tái sử dụng cho nhiều mục đích, cũng như khám phá các kỹ năng khác nhau trong quá trình hợp thành và tạo ra các mô-đun mới.
AI Copilot của Microsoft là một thử nghiệm tận dụng cả hai cách tiếp cận của mô hình LLM thông thường (ChatGPT) và mô hình LLM tăng cường. Chức năng đo lường độ thỏa dụng (utility function) đóng vai trò như một giám khảo: cho điểm và phản hồi kết quả đầu ra để giải quyết vấn đề ảo giác. Theo TS. Gao, chức năng này rất gần với khái niệm “siêu ngã nhân tạo” mà TS. Cerf đề cập phía trước.
TS. Bùi Hải Hưng: ChatGPT chưa thật sự sẵn sàng cho hơn một nửa dân số thế giới
Theo góc nhìn của TS. Bùi Hải Hưng, việc chấp nhận và sử dụng ChatGPT đang diễn ra ở mức nhanh chưa từng có, và việc đón nhận các công nghệ mới sẽ ngày càng nhanh hơn nữa. Tuy nhiên, công cụ này chưa sẵn sàng cho những người không dùng tiếng Anh như ngôn ngữ chính, tương đương với khoảng 50% dân số thế giới. Đây được gọi là nhóm ngôn ngữ ít tài nguyên – những ngôn ngữ không phổ biến trong các giao dịch thương mại quốc tế và ít được đầu tư các nguồn lực về chuyên môn, thời gian cũng như tài chính.
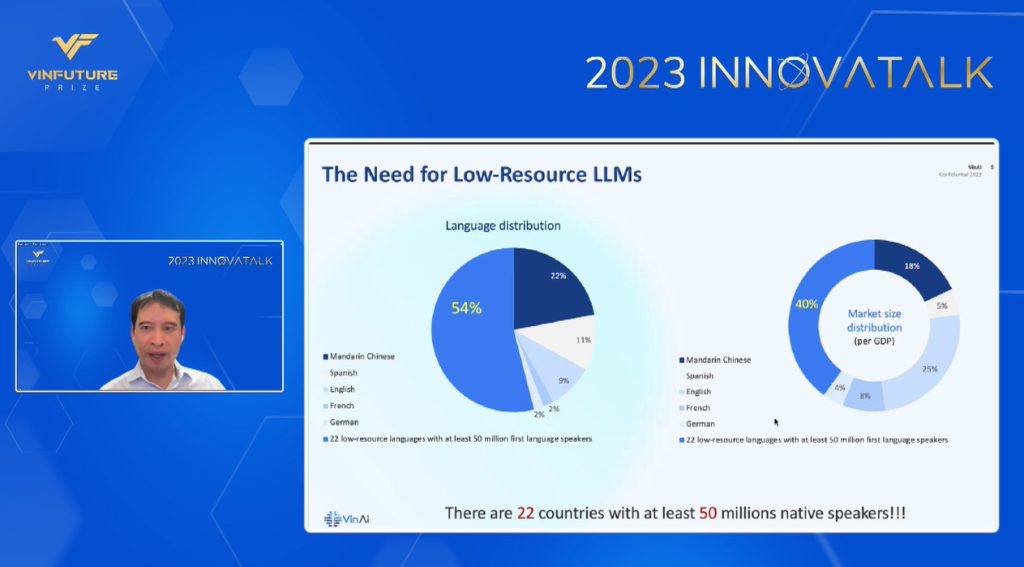
Bài trình bày của TS. Hưng dẫn số liệu cho thấy có ít nhất 22 quốc gia cùng 50 triệu người dân nói tiếng bản địa được xếp vào nhóm ngôn ngữ ít tài nguyên này, trong đó có Việt Nam. Tính theo GDP, khu vực này chiếm đến khoảng 40% tổng GDP toàn cầu. “ChatGPT vẫn chưa sẵn sàng để phục vụ thị trường này”, TS.Hưng nói.
Cụ thể, hiện nay vẫn còn thiếu những LLMs chất lượng cao được đào tạo bài bản, các kho dữ liệu mở, cũng như ngữ liệu văn bản tốt dành riêng cho các ngôn ngữ ít tài nguyên. Hơn nữa, việc có quá ít nguồn lực được đầu tư và các kiến thức sẵn có khiến cho vấn đề ảo giác trở nên nghiêm trọng hơn trong các ngôn ngữ này. Các mô hình LLMs hiện tại khi sử dụng bằng ngôn ngữ ít tài nguyên thường cho ra các kết quả sai lệch, cũng như chưa tạo ra được các đoạn văn mượt mà và tự nhiên.
TS. Hưng dẫn chứng việc sử dụng ChatGPT bằng tiếng Việt để minh họa cho các hạn chế này. Ông đã thử hỏi ChatGPT-4 về tác phẩm “Tắt đèn” của Ngô Tất Tố và bài hát “Cây đàn sinh viên” nổi tiếng do ca sĩ Mỹ Tâm trình bày – những chủ đề mà phần lớn người Việt Nam sẽ biết. Chatbot này vẫn đưa ra được câu trả lời, nhưng hoàn toàn sai. ChatGPT-4 thậm chí cho rằng Trịnh Công Sơn đã sáng tác bài “Cây đàn sinh viên” vào năm 1958.
TS. Hưng và các kỹ sư của VinAI đã thử xây dựng một vài mô hình ngôn ngữ lớn dành riêng cho tiếng Việt. Mặc dù cần thêm nhiều nỗ lực đào tạo cũng như tinh chỉnh mô hình, các thử nghiệm này cho thấy tiềm năng lớn trong việc giải quyết các vấn đề cốt lõi của LLMs cho các ngôn ngữ ít tài nguyên. Trong đó, nguyên nhân đơn giản có thể là do các yếu tố địa phương và văn hóa chưa được cân nhắc vào quá trình đào tạo mô hình.
Theo TS. Hưng, các mô hình ngôn ngữ lớn dành cho ngôn ngữ ít tài nguyên vẫn phải đảm bảo khả năng học theo ngữ cảnh, tuân thủ hướng dẫn, và lập luận dựa vào quy trình từng bước một trong khi duy trì được hiệu quả tính toán. Chúng sẽ tạo ra thị trường mới cho LLMs, đồng thời đảm bảo độ tin cậy cho của mô hình cho các người dùng ở đa dạng địa phương.
“Xây dựng LLMs dành cho ngôn ngữ ít tài nguyên là một trong những chìa khóa quan trọng để mang mô hình ngôn ngữ lớn tới toàn thế giới. Tiếng Việt là một vùng ngôn ngữ màu mỡ để thử nghiệm việc này.” Ông hy vọng các tập đoàn công nghệ lớn dành nhiều sự quan tâm hơn đến các ngôn ngữ không phổ biến, từ đó tạo ra nhiều lợi ích mới cũng như tăng khả năng tiếp cận của công nghệ AI cho mọi người, bất kể họ ở đâu.
Thảo luận: Ứng dụng AI để phát triển cuộc sống con người
Ở phần thảo luận, các chuyên gia tiếp tục trao đổi những nguy cơ liên quan đến việc chatbot tạo ra các câu trả lời quá giống với con người. Rủi ro của việc này là rất lớn đối với các lĩnh vực yêu cầu tính chính xác và an toàn cao, chẳng hạn như lĩnh vực y tế hay các giao dịch tài chính. Vậy làm cách nào để đảm bảo rằng AI tạo ra các phản hồi an toàn cho người dùng?
TS. Jianfeng Gao nhấn mạnh tầm quan trọng của việc thông báo cho người dùng về các hạn chế của LLMs để họ có kỳ vọng hợp lý. Việc phát triển các mô hình này cũng cần phải được thực hiện cẩn trọng, để đảm bảo người dùng và các ngành liên quan có thể thích ứng tốt với các thay đổi.
“Tôi nghĩ chúng ta nên tạo cho LLMs khả năng trả lời “Tôi không biết’”, TS. Hưng nêu ý kiến.. Ông Hưng nhấn mạnh rằng để trả lời “không biết” cũng cần nhiều suy nghĩ, và chúng ta nên lấy đó là lựa chọn cuối cùng cho những câu hỏi vượt quá khả năng, thay vì để cho AI tùy tiện tạo ra những câu trả lời tiềm ẩn nhiều rủi ro. TS. Cerf rất tán thưởng ý kiến này.
Khi phản hồi câu hỏi từ một sinh viên về khả năng rút ngắn quy trình đào tạo LLMs bằng cách sửa lỗi cho ChatGPT ngay trong quá trình trao đổi, TS. Hưng nói rằng tinh chỉnh mô hình có thể là giải pháp, nhưng việc này đòi hỏi rất nhiều công sức. Quan trọng hơn, vấn đề không phải chỉ là nạp thêm dữ liệu cho các LLMs, mà còn là điều chỉnh sao cho công nghệ hiện tại có thể tối ưu hóa các nguồn lực hiện có.
Tác động của AI đối với giáo dục và thi cử cũng được các khán giả nêu ra trong phần trao đổi tại buổi hội thảo. TS. Cerf cho rằng sự phổ biến của AI khiến chúng ta phải chuyển trọng tâm từ việc đánh giá kết quả sang đánh giá quá trình. Mặc dù AI có khả năng vượt trội trong việc tạo ra các kết quả chuẩn xác, nhưng điều quan trọng ở đây là chúng ta phải giải thích được cách tìm ra kết quả đó và tiến bộ dần thông qua việc học từ những lỗi sai của chính mình.
TS. Xuedong Huang đồng tình với ý kiến này. Ông nhấn mạnh thêm rằng sự trỗi dậy của AI báo hiệu một cuộc cách mạng quan trọng trong giáo dục, đặc biệt là ở các nước châu Á. Khu vực này vẫn đang đặt trọng tâm quá lớn vào việc ghi nhớ và lặp lại, trong khi chúng ta cần phải chuyển sang học cách tạo ra kiến thức mới cho xã hội. Các LLMs sẽ đóng vai trò dự báo các sai lầm tiềm tàng và kiểm tra khả năng áp dụng của các ý tưởng trong thế giới thực.
Mục tiêu của các công nghệ AI không phải là thay thế con người mà là cải thiện và nâng cao đời sống con người. Các chuyên gia tại hội thảo cho rằng không nên quá lo lắng, mà thay vào đó hãy học cách giao nhiệm vụ cho AI một cách khôn ngoan.
“Tôi nghĩ AI sẽ mở ra nhiều cơ hội hơn cho con người, cũng giống như điều các công nghệ trước đây đã làm được. Nên hiểu rằng ChatGPT chỉ lặp lại các thông tin sẵn có chứ nó không bổ sung được gì. Vì vậy, con người nên tập trung vào việc tạo ra các giá trị mới”.
TS. Jianfeng Gao khuyến khích các học giả nên tận dụng ChatGPT trong việc tổng quan tài liệu khi làm nghiên cứu: “Nếu tác vụ cần thực hiện là tóm tắt lại 300 bài nghiên cứu mà hầu hết đã lỗi thời, bạn nên giao cho ChatGPT, và dùng thời gian đó để xem phim cùng gia đình.”









